
[Paper Review] Visually-Prompted Language Model for Fine-Grained Scene Graph Generation in an Open World (CaCao)
Published:
BERT 기반 data augmentation을 이용하여 scene graph generation 분야의 predicate imbalance 문제를 개선한 연구입니다.
Motivation
Scene Graph Generation 분야에서는 predicate imbalance 문제가 주요 연구 주제 중 하나입니다. Predicate imbalance 는 Visual Genome 등의 SGG 학습 데이터셋에서, informative/fine-grained predicate을 포함한 triplet이 frequent/coarse-grained predicate을 포함한 triplet에 비해 적은 현상을 의미합니다. 아래 왼쪽 그래프에서 확인할 수 있듯이, on/has와 같은 coarse-grained predicate의 개수가 carrying/laying on과 같은 fine-grained predicate 보다 압도적으로 많습니다.
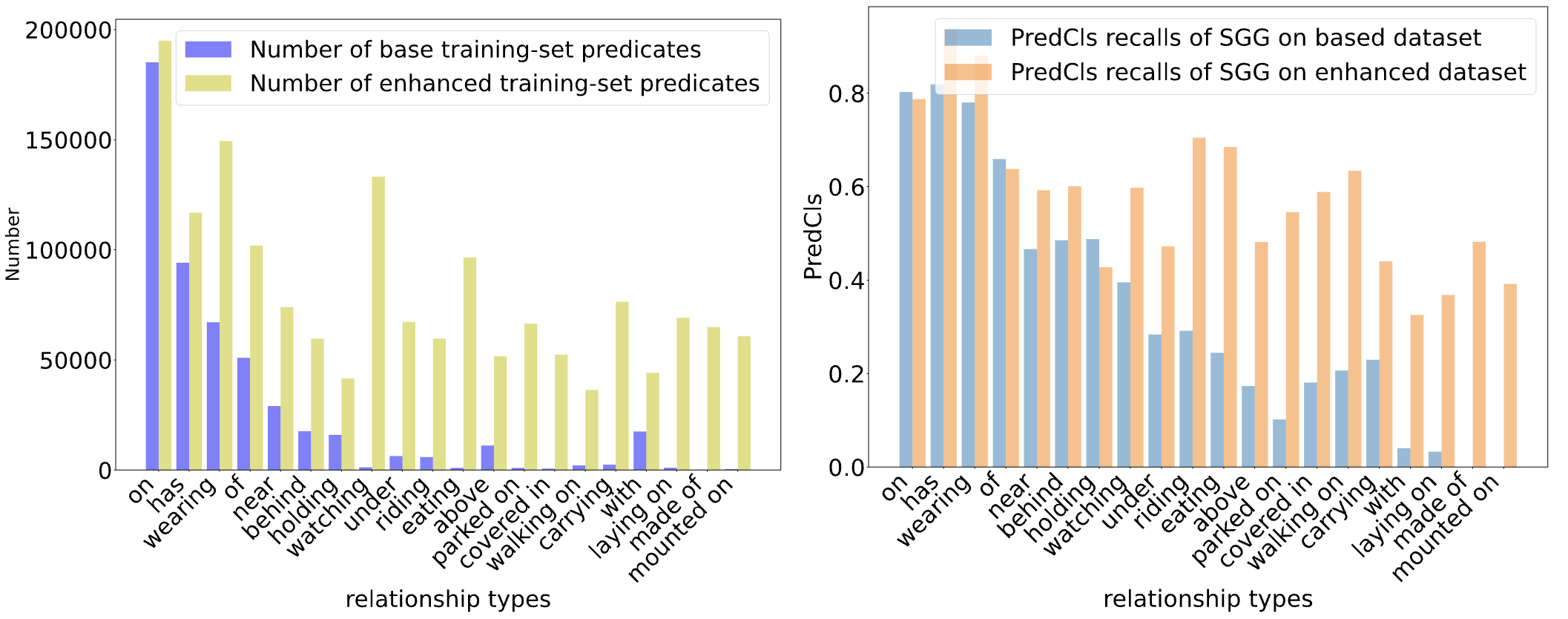
위와 같은 predicate의 long-tail distribution은, SGG 모델 성능 하락의 큰 원인이 됩니다. Predicate imbalance로 인해, 모델이 대부분의 relationship을 on, has와 같은 coarse-grained predicate으로 예측해버리는 현상이 나타나는 것입니다. 위 오른쪽 그래프에서, 모델의 예측성능(Recall@K)이 fine-grained predicate에 대해서는 매우 낮은 것을 확인할 수 있습니다.
Predicate imbalance 문제를 해결하기 위해 여러 방법론이 제안되었습니다. 대표적으로 causality에 기반한 TDE, reweighting에 기반한 VCTree가 있습니다.
위와 같은 여러 선행연구에서 여러가지 방법으로 predicate imbalance에 보다 robust한 SGG 모델을 학습할 수 있음을 보였지만, 본 논문에서는 기존 선행연구들의 한계점을 아래와 같이 지적하였습니다.
- 대부분이 hand-designed rule에 기반하여 unscalable하다.
- Source data, model architecture에 따라 hyperparameter의 세밀한 조정이 필요하다.
- Prior data distribution에 의존한다.
이러한 한계점에서 벗어나기 위해, 저자는 pretrained language model (BERT)의 extensive knowledge 사용을 제안하였습니다. Large-scale dataset에서 사전학습된 언어 모델이 informative relationship에 대한 정보를 잘 알고 있을 것이라는 가정에 기반한 것입니다.
이를 위해 BERT에 기반하여 기존 데이터셋에서 tail predicate이 포함된 triplet을 증강해주는 Cross-modal prediCate boosting (CaCao) data augmentation framework를 제안하였습니다. CaCao를 통해 Visual Genome 등의 기존 데이터셋을 증강하고, 이를 SGG 모델의 학습에 이용하여 성능을 개선하는 방식입니다.
Key Idea
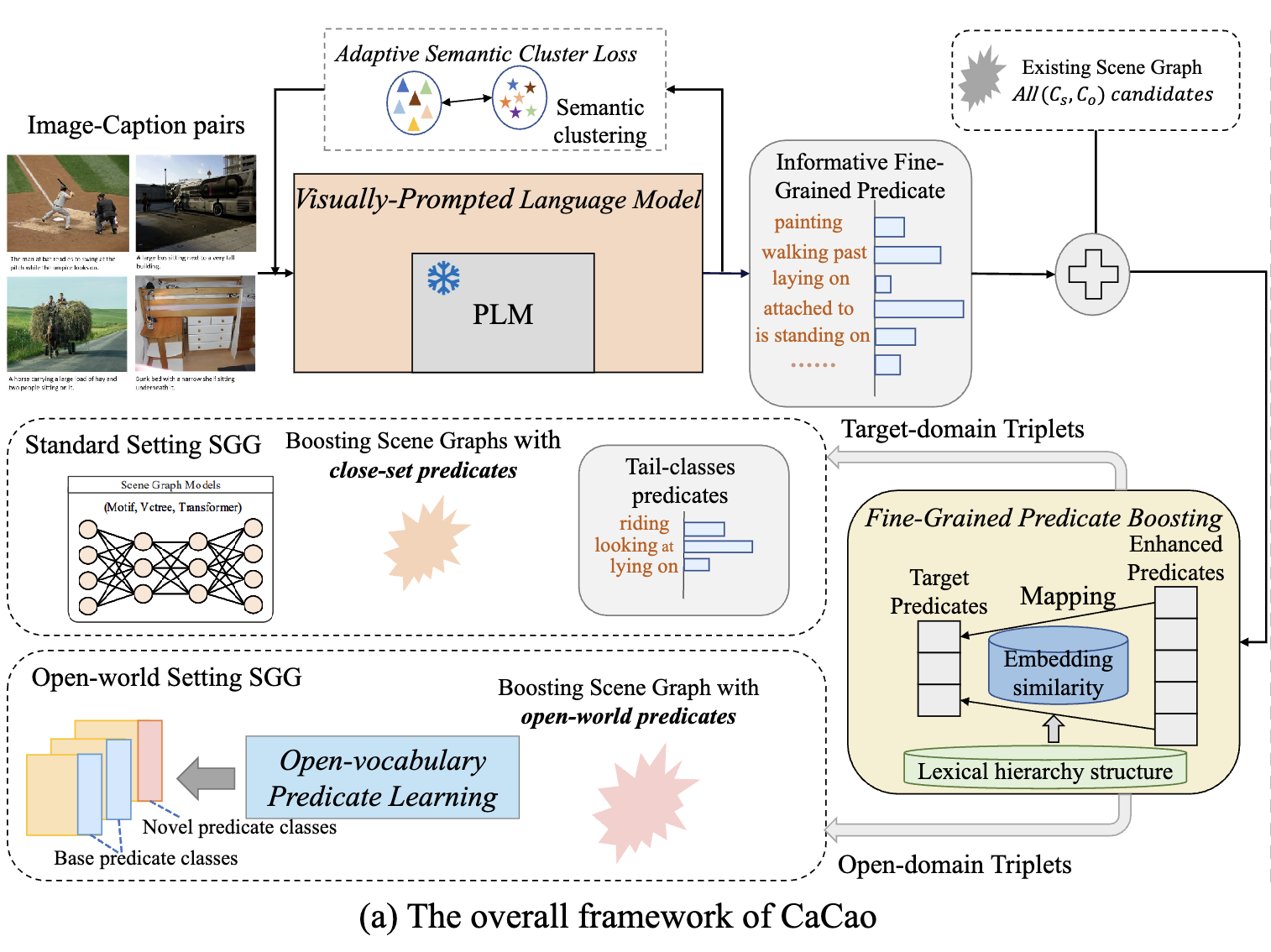
CaCao framework는 내부적으로 BERT 기반의 Visually-Prompted Language Model을 가지고 있으며, COCO 데이터셋의 image, triplet pair로 Visually-Prompted Language Model을 학습합니다. 이후 학습이 완료된 모델을 이용해 기존 데이터셋의 unlabeled object pair에 대한 labeling을 진행하여 데이터셋을 증강하게 됩니다. Unlabeled object pair는 Visual Genome을 예로 들면 bounding box coordinate을 이용하여 object 간의 IoU를 계산한 후, 특정값 이상이며 아직 레이블링 되어있지 않은 조합을 의미합니다.
COCO 데이터셋의 경우 저자가 uninformative, frequent predicate을 제거하는 전처리를 적용하여 585 종류의 informative predicate을 가지고 있는 상태입니다. 따라서 이 데이터셋을 학습한 Visually-Prompted Language Model은 informative predicate을 예측할 수 있게 됩니다. 단, COCO 데이터셋과 Visual Genome 등의 SGG 데이터셋의 label은 다릅니다. 따라서 데이터셋 증강 시에는 모델이 COCO의 informative predicate으로 예측하면 이를 증강하는 데이터셋의 적절한 label과 mapping하게 됩니다.
Visually-Prompted Language Model
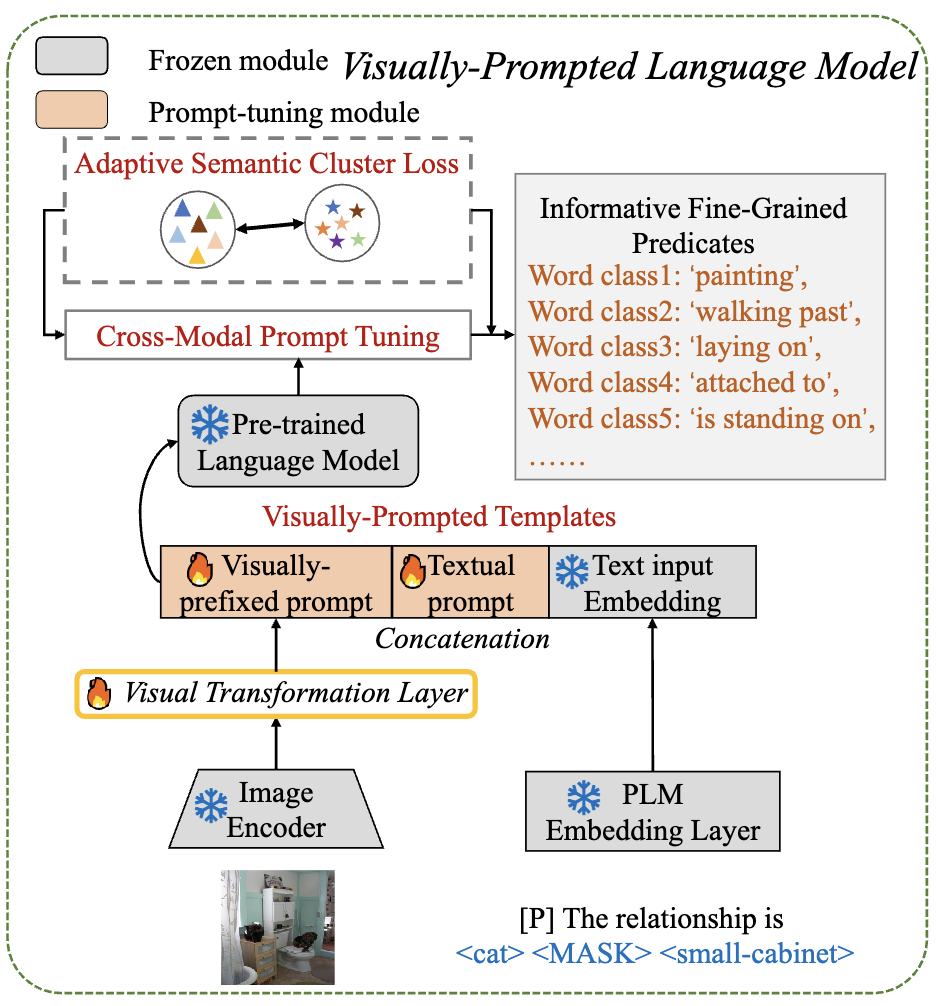
Visually-Prompted Language Model의 내부적인 구조는 위와 같습니다. Pre-trained Language Model은 Frozen BERT를 의미하며, Image Encoder는 Frozen ViT를 이용합니다. 모델이 내부적으로 학습하는 것은 오직 Visual Transformation Layer 및 Textual prompt 입니다.
Visual Transformation Layer는 image, text 간의 modality gap을 해소하기 위해 도입되었습니다. BERT는 원래 언어 정보만 인식할 수 있어, SGG에 필요한 visual feature를 직접 제공할 수 없습니다. 따라서 visual feature를 text modality로 변환시키는 Visual Transformation Layer를 도입하여 이미지 정보를 함께 프롬프트로 제공하게 됩니다. Visual Transformation Layer는 내부적으로 MultiheadAttention, Feed Forward로 구성된 하나의 self attention module로 구현되어 있습니다.
Textual propmt는 정확한 용도를 제가 이해하지는 못했지만(논문에서는 efficient text prompt engineering을 위해서 도입되었다고 합니다) 보다 visual information과 text가 잘 융합되도록 해주는 역할로 생각하고 넘어갔습니다. 구현 상에서는 learnable token 10개로 구성하였습니다.
Visually-Prompted Language Model의 inference 과정은
- Image Encoder & Visual Transformation Layer, PLM Embedding Layer가 각각 image, triplet (e.g. [apple][MASK][table])을 prompt로 인코딩합니다.
- 이후 textual prompt와 concatenation을 진행하여 전체 prompt를 완성한 후 BERT에 전달합니다.
- BERT는 제공받은 prompt를 처리합니다.
- BERT의 마지막 layer의 embedding 값을 classifier (linear layer)에 전달하여 최종 logit을 계산합니다.
- Logit 값을 이용해서 [MASK] 자리에 알맞는 predicate을 예측합니다.
이제 Visually-Propmted Language Model의 training에 대해서 다루어보겠습니다. Training 과정에서 학습하는건 visual transformation layer, textual propmt 입니다. 모델이 image, triplet pair를 제공받으면, 위 inference 과정과 동일하게 동작하고 최종적으로 logit을 도출해 냅니다. 이후에 logit에 softmax를 적용한 후 변형된 cross entropy loss로 학습을 진행합니다. 하나의 (image, triplet) pair에 대해서 objective는 아래와 같이 정의됩니다.
Adaptive Semantic Cluster Loss (ASCL)
\[-\min \Sigma^{N_p}_{i=1} \mathop{\mathbb{E}}_\epsilon[\phi(y_i) + \Sigma _{j \in C_i} \frac{\epsilon_{i, j}}{|C_i|} \phi(y_j)] \log \psi(y_i | X_i)\]여기서 $\psi(y_i | X_i)$ 는 input prompt $X_i$ 의 masked position에 대한 probability distribution 입니다. $\phi(y_i)$ 는 ground-truth label을 나타내는 one-hot vector를 의미합니다.
\[\mathop{\mathbb{E}}_\epsilon[\phi(y_i) + \Sigma _{j \in C_i} \frac{\epsilon_{i, j}}{|C_i|} \phi(y_j)]\]일반적인 cross entropy loss의 경우 위 부분이 $\phi(y_i)$ 여야 하지만 CaCao에서는 이를 조금 변형하여 사용합니다. Predicate은 그 종류가 매우 다양하기 때문에 철자가 서로 다른 predicate이라도, 문맥상 비슷한 의미를 가지고 있는 경우가 있습니다(논문에서는 이를 semantic co-reference라고 부릅니다). 그러나 위 objective에 $\phi(y_i)$ 만을 사용한다면 예를 들어 ‘on’이 정답인 triplet에 대해 ‘above’라는 예측을 하였을 경우, 어느정도 비슷함에도 아예 다른 예측을 하였을 때와 동일하게 penalize 됩니다. 그렇게 된다면, 모델의 학습이 어려워지고 augmentation에 필요한 diversity를 얻기에도 어려워집니다.
이를 개선하기 위해 CaCao의 학습에는 위와 같은 loss가 사용됩니다 (Adaptive Semantic Cluster Loss라고 논문에서 부릅니다). Loss 계산 방식은 우선 COCO 데이터셋의 predicate 별로 embedding을 계산합니다. Embedding은 <subject-predicate-object> 형태의 triplet이 있을 때, 이를 BERT에 넣고 마지막 layer의 embedding을 가져옵니다. 특정 predicate이 포함된 모든 triplet에 대해 동일하게 embedding을 계산하고 이를 평균 내주면 해당 predicate의 임베딩이 되는 방식입니다.
이후 predicate embedding 전체에 대해 K-Means Clustering을 진행합니다. 클러스터의 개수는 논문의 구현 상에서는 39로 하였으나 해당 값으로 결정하게 된 근거는 찾지 못하였습니다. 클러스터링 이후 특정 label $y_i$ 에 대해서 $y_i$ 와 동일한 클러스터 내부에 있는 레이블을 함께 고려해주도록 하는 것이 위 수식의 의미가 됩니다. 같은 클러스터에 있는 다른 label에는 $\frac{\epsilon_{i, j}}{|C_i|}$ 만큼의 가중치가 붙는데 $\epsilon_{i, j}$는 i, j predicate embedding 간의 cosine similarity 값을 의미합니다.
저자는 위 방식을 통해, 모델이 최대한 다양한 informative predicate을 예측하도록 유도할 수 있다고 주장하였습니다. 이를 위해서, $\psi(y_i | X_i)$ 도 일반적인 softmax에서 조금 변형하였습니다.
\[\psi(y_i | X_i) = \frac{\exp({z_i})}{\Sigma_{j=1}^{K} w_{i, j}\exp({z_j})} \ w_{i, j} = \delta \frac{z_j}{z_i} \frac{n_j}{n_i}\]$z_i, z_j$는 logit 값을 의미하며 $n_i, n_j$는 i, j predicate의 초기 개수는 의미합니다. 위의 변형된 softmax를 통해 모델이 특정 predicate 만 과도하게 생성하는 것을 방지할 수 있었다고 합니다.
Epic
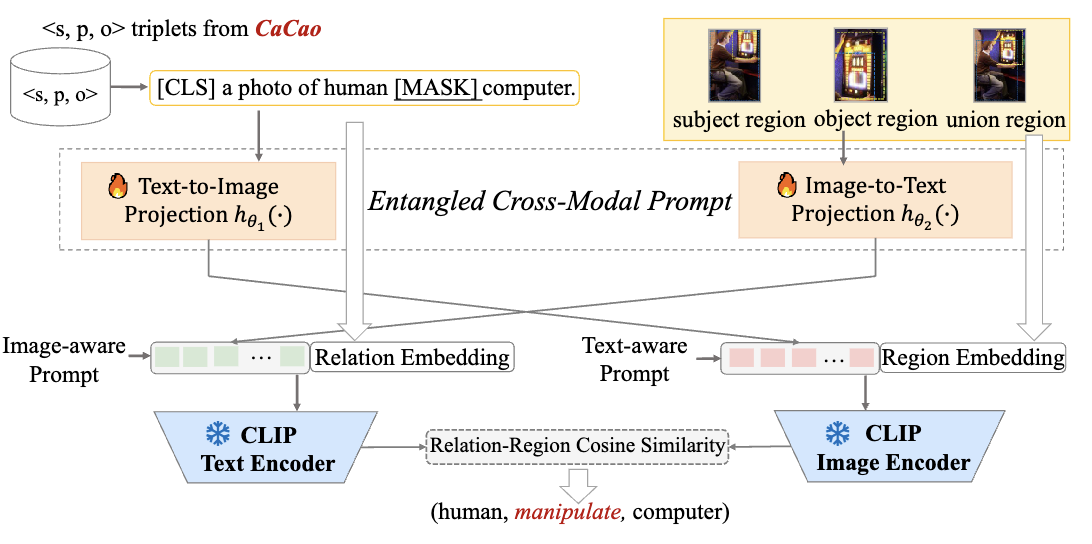
CaCao를 이용하면 데이터셋을 효과적으로 증강한 후에 IMP, Motifs 등의 SGG 모델의 학습에 이용할 수 있습니다. 논문에서는 더 나아가 Open-World Predicate SGG 모델 구조를 제안하였습니다. Entangled cross-modal prompt approach for open-world predicate scene graph generation (Epic)으로 명명되며 구조는 아래와 같습니다.
Experiments
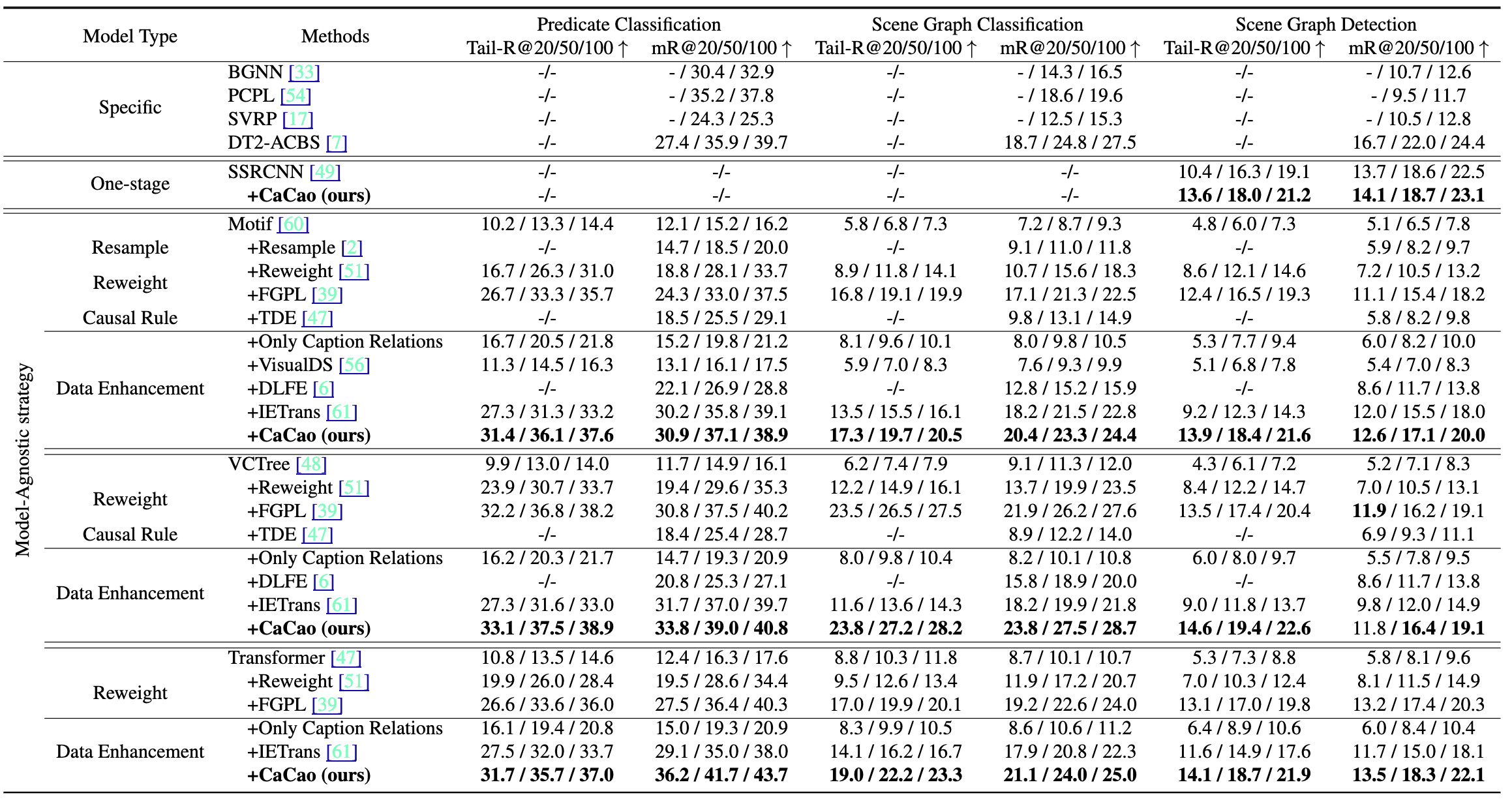
주요 SGG 모델을 CaCao로 학습하였을 때 위와 같이 기존 방법들보다 성능을 향상 시킬 수 있었다고 합니다. 저자는 predicate imbalance에 robust하기 위해 R@K가 아닌 mR@K를 사용하였으며, tail predicate에 대한 성능을 보다 면밀하게 측정할 수 있도록 빈도수 하위 50% predicate에 대해서만 성능을 측정한 Tail-R@K도 사용하였습니다.
Conclusion
Data augmentation을 기반으로 predicate imbalance 문제를 해결한 연구는 있었으나 open world knowledge를 이용한건 본 논문이 처음인듯 합니다. 보통 Open-World SGG 모델을 새로 구축하는 연구들은 꽤 있었는데 Open-World로 데이터셋을 증강하고 closed SGG에 적용하는 접근도 있다는 것을 알게 되었습니다. 추가로, 본 논문의 github에서 확인해보니 클러스터링이 제대로 된 것인지 조금 의문이 들기는 합니다. 클러스터 개수 K도 적절한 것인지, 원소가 하나만 있는 클러스터도 있던데 괜찮은 것인지, K-Means 이외의 다른 방식은 없는지에 대한 고민을 해보면 좋을 것 같습니다.
읽어주셔서 감사합니다 :)