
[Paper Review] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ViT)
Published:
ViT의 구조를 간단히 다루어보고, 논문의 Experiments/Appendix 위주로 리뷰해보았습니다.
Motivation
NLP 도메인에서 Self-Attention 기반 모델 (e.g. Transformer)가 널리 활용되고 있었습니다. 특히 large-scale dataset에서 pre-training을 진행한 후에 downstream task로 transfer 하는 방식이 주로 사용됩니다. 그러나 CV 도메인에서는 CNN 기반 모델이 아직 주류를 이루고 있었습니다. Attention과 CNN을 결합하거나, 또는 완전히 Attention으로 대체한 연구가 있긴 했으나 후자의 경우 흔히 생각하는 attention 과는 다르고 아직 ResNet 기반 구조가 SOTA 인 상태입니다.
저자는 Transformer를 이미지에 적용하면 CV 도메인에서도 Transformer의 강력한 장점(receptive field, generalization, etc.)을 활용할 수 있을 것이라고 생각하여 ViT를 제안하게 되었습니다.
Key Idea
아래는 ViT의 전체적인 구조입니다. 저자는 Transformer가 NLP 도메인에서 보여줬던 장점을 최대한 유지하기 위해, Transformer의 기존 구조를 최대한 변경하지 않도록 하였습니다.
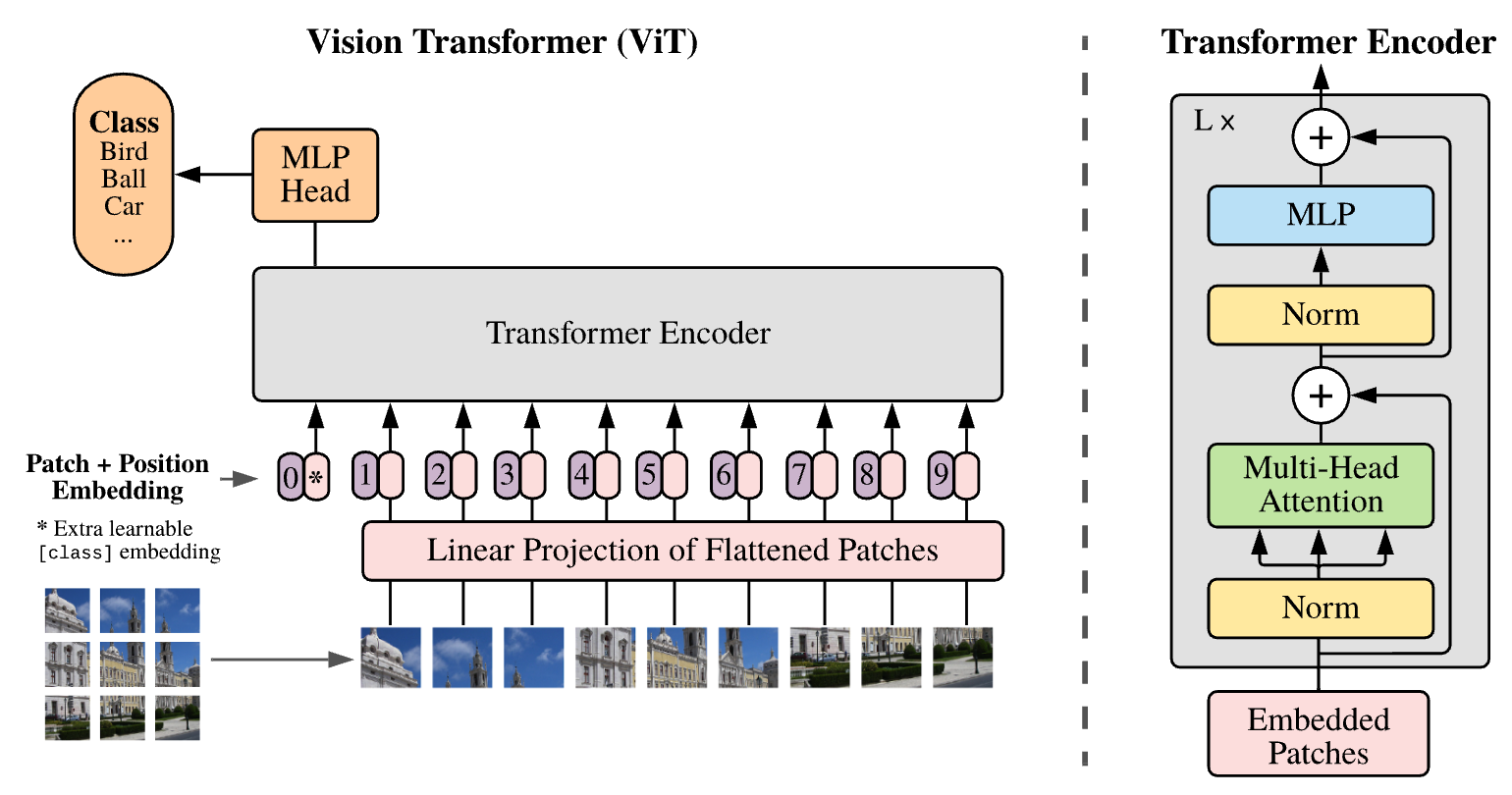
Model Architecture
이미지를 sequence 형태로 표현하기 위해서 저자는 이미지를 non-overlapping patch로 나누는 방식을 선택하였습니다. 즉 $\mathbb{R}^{H \times W \times C}$ 의 이미지가 있을 때 이를 $\mathbb{R}^{N \times (P^2C)}$ 로 바꾸는 것입니다.
ViT 내부의 Transformer는 latent vector dimension을 D로 유지하므로 $\mathbb{R}^{P^2C}$ 를 $\mathbb{R}^D$ 로 매핑해야합니다. 이를 위해 flattened image patch는 Linear Projection of Flattened Patches layer를 거치게 됩니다.
이후에 image patch 별로 1D positional encoding vector가 결합됩니다. 논문에서는 2D positional encoding 등 보다 고차원적인 방법들과 1D의 성능 차이가 그리 크지 않아 1D PE를 사용했다고 합니다. 이 과정에서 sequence의 첫 시작 부분에 새로운 learnable embedding이 추가됩니다. 이 embedding은 이후 Transformer에서 image patch와 함께 인코딩 되어 이미지의 전체적인 정보를 저장하게 되고, 최종 단계에서 classification에 활용됩니다.
PE를 거친 sequence는 Transformer를 거쳐 인코딩되고 이후 0번째 embedding이 MLP head에 주어져 image classification을 수행합니다. MLP head는 GELU nonlinearity를 이용한 2개의 linear layer로 구성되어 있다고 합니다.
Hybrid Architecture
처음에 input sequence를 생성할 때 raw image를 patch로 나누는 것이 아닌, CNN을 거친 feature map을 사용하는 방식으로 진행하는 hybrid architecture도 사용이 가능하다고 합니다.
Inductive bias
Inductive bias는 모델이 unseen sample에 대한 prediction을 할 때 기반하는 모든 가정 을 의미합니다.
예를 들면 CNN 계열 모델의 inductive bias는 아래와 같을 것입니다.
- Input data는 2D structured data 일 것이다.
- Input data에 대한 convolution은 translation equivariant 할 것이다.
- Input data는 locality를 가질 것이다.
위 가정에 기반하여 CNN 모델은 local area에 filter를 적용하여 이미지를 처리하게 됩니다.
Transformer의 inductive bias는 아래와 같을 것입니다.
- Input data는 sequence 형태일 것이다.
- Input data 각각은 positional encoding이 진행되었을 것이다.
- Input data 간의 pairwise relation learning을 통해 패턴을 발견할 수 있을 것이다.
Inductive bias가 많을 수록 모델이 직접 학습, 처리해야하는 부분이 줄어드므로 더 효율적인 모델을 설계할 수 있을 것입니다. 반면 inductive bias에 부합하는 상황에만 모델을 적용할 수 있으니 일반성은 떨어지게 됩니다. Inductive bias가 적으면 모델이 직접 학습해야하는 것들이 늘어나므로 더 많은 데이터를 제공해주어야 합니다. 학습 비용 등은 더 들지만 모델의 일반성은 더 향상되는 것입니다.
Transformer는 CNN보다 더 일반적인 inductive bias를 가지기에 많은 학습 데이터를 필요로 하지만 다양한 도메인에 적용이 가능한 것입니다. ViT도 Transformer에 기반하기에 많은 학습데이터를 제공해주어야 합니다. ImageNet-1k 정도의 mid-size dataset으로 학습한 경우 CNN 계열 모델이, ImageNet-21k 정도의 large-scale dataset의 경우에는 ViT의 성능이 더 좋았다고 합니다.
Fine-Tuning and Higher Resolution
ViT를 finetuning 할 때는 일반적으로 이미지의 해상도를 높혀서 진행합니다. 이미지의 해상도가 커지면 동일한 patch size에서 자연스레 sequence의 길이도 길어지게 됩니다. 이때 pre-training에 맞춰진 positional embedding vector의 개수가 부족해질 수 있습니다. 논문에서는 이를 2D interpolation으로 해결했다고 합니다.
Experiments
- ViT, ResNet, Hybrid를 서로 비교하는 방식입니다.
- 각 모델에 적절한 data requirement, 모델별 pre-training cost 등을 측정하였다고 합니다.
Setup
Datasets
이미지 및 데이터셋에 대한 전체적인 전처리는 BiT의 방식을 적용했다고 합니다.
Pre-training에 사용된 데이터셋은 아래와 같습니다.
- ILSVRC-2012 ImageNet (1k classes, 1.3M images)
- ImageNet-21k (21k classes, 14M images)
- JFT (18k classes, 303M images)
Fine-tuning에 사용된 데이터셋은 아래와 같습니다.
- ImageNet
- CIFAR-10/100
- Oxford IIIT-Pets
- Oxford Flowers-102
Pre-training 데이터셋의 이미지 중에서 Fine-tuning 데이터셋의 test set에 있는 이미지는 data leakage를 방지하기 위해 제거했다고 합니다.
Model Variants
ViT의 경우 아래와 같이 모델 종류를 정의했습니다. ViT-B/16 으로 표기된 경우 ViT Base 크기의 모델이며 patch size가 16 x 16 임을 의미합니다.

CNN 기반의 모델의 경우 ResNet을 개량한 “ResNet (BiT)”를 사용했습니다. 변형된 부분은 아래와 같습니다.
- Batch Normalization을 Group Normalization으로 변경
- Standard Convolution
- 위 변화가 transfer 되었을 때의 성능을 증가시켜준다고 합니다.
Training & Fine-tuning
ViT 및 ResNet (BiT) 모든 모델을 Adam optimizer로 학습하였습니다. 세부 설정은 아래와 같습니다.
- $\beta_1 = 0.9, \beta_2 = 0.999$
- Batch size = 4096
- Weight decay = 0.1
- Linear learning rate warmup & decay
ImageNet에서 pretrain 하고 ImageNet에서 다시 finetune 한 경우에는 이미지의 resolution이 finetuning 할 때 증가되었다고 합니다.
Metrics
Pretraining이 완료된 이후에, 모델의 downstream task에 대한 성능을 측정하기 위해 논문에서는 두 가지 평가지표를 사용하였습니다.
첫 번째는 Fine-tuning accuracy 입니다. 이 방법은 pretrained 된 모델을 finetuning한 후 accuracy를 측정하는 일반적인 방법입니다.
그러나, finetuning cost로 인해 위 방법으로 측정하기 어려운 경우 논문에서는 Few-shot accuracy를 사용했습니다. Few-shot accuracy는 finetuning dataset의 training image 중 일부만 이용하여 모델의 성능을 측정하는 방식입니다. Linear 5-shot accuracy를 구한다고 가정했을 경우, training set에서 class 별로 5개의 이미지를 샘플링하고 least square objective로 regression 모델을 학습합니다. label은 각각의 entry가 [-1, 1] 범위인 K-dimensional 벡터를 사용합니다.
Comparison to State of the Arts
비교군이 되는 기존 CNN 기반 모델은 아래와 같습니다.
- Noisy Student: ImageNet에서 SOTA이며 large EfficientNet 기반 모델
- BiT-L: Large ResNet 기반. ImageNet 이외 다른 벤치마크에서 SOTA
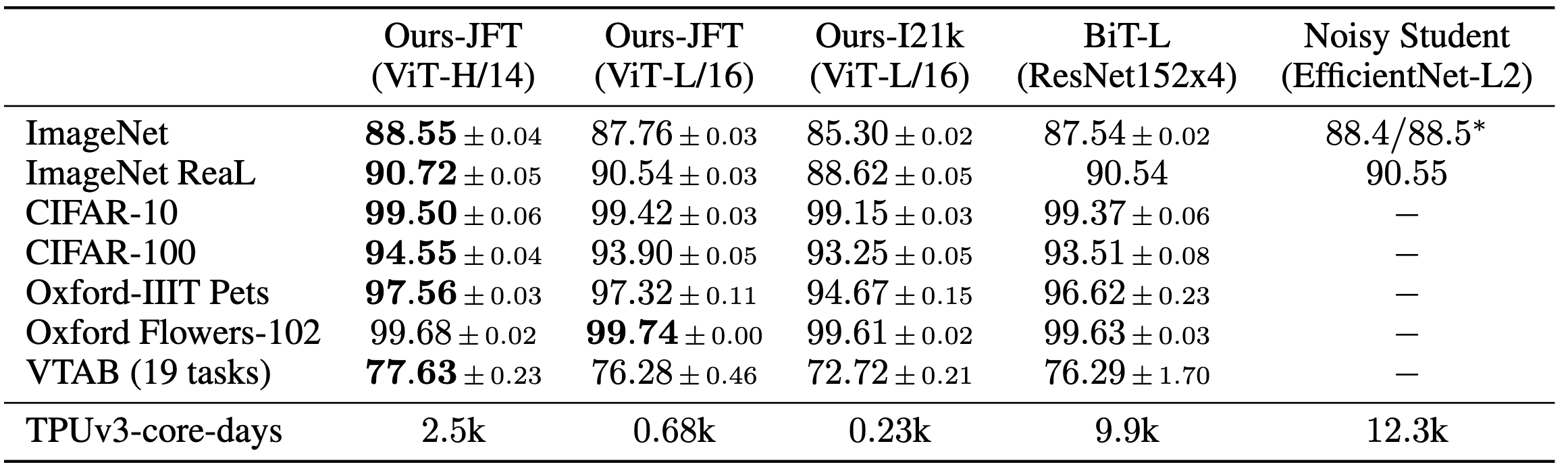
위 결과에 따르면 ViT는 BiT-L, Noisy Student 기반 모델과 image classification 성능이 비슷하거나 더 높은 것을 확인할 수 있습니다. Pretraining -> Finetuning이 아닌 일반적인 CNN 모델의 성능과 비교해보아도 우수한 모습을 보여줍니다.
특히나 주목해야할 부분은 TPUv3-core-days 지표입니다. TPUv3-core-days는 해당 모델을 pretraining 하는데에 며칠이 걸리는지 나타낸 지표입니다. 예를 들어 제가 TPUv3 8 core로 pretraining을 진행한다면, ViT-L/16을 ImageNet-21k에서 pretraining 하는데에는 $\frac{0.23k}{8} \approx 29$ 일이 소요되는 것입니다. TPUv3가 A100 정도 GPU와 비슷한 성능이라고 하는데, 한 달도 정말 길지만 그래도 ViT가 BiT-L, Noisy Student 보다는 pretraining cost가 확실히 적은 것을 알 수 있습니다.
결론적으로는 ImageNet-21k에서 ViT-L/16을 pretraining 하는 것이 가장 pretraining cost도 적고 좋은 downstream performance를 얻을 수 있는 방법인 것 같습니다.
Pre-Training Data Requirements
저자는 inductive bias의 차이를 극복하기 위해서는 dataset size가 어느정도로 커져야 하는 지를 두 가지 실험을 통해 알아보았습니다.
첫 번째는 pretraining dataset을 ImageNet, ImageNet-21k, JFT-300M으로 점점 키우면서 ImageNet에서의 정확도를 측정한 것입니다. ImageNet에서 pretraining하고 ImageNet에서 finetuning하는 것이 이상해 보이실 수 있는데 이때 이미지의 resolution을 finetuning할 때에는 더 증가시켰다고 합니다.
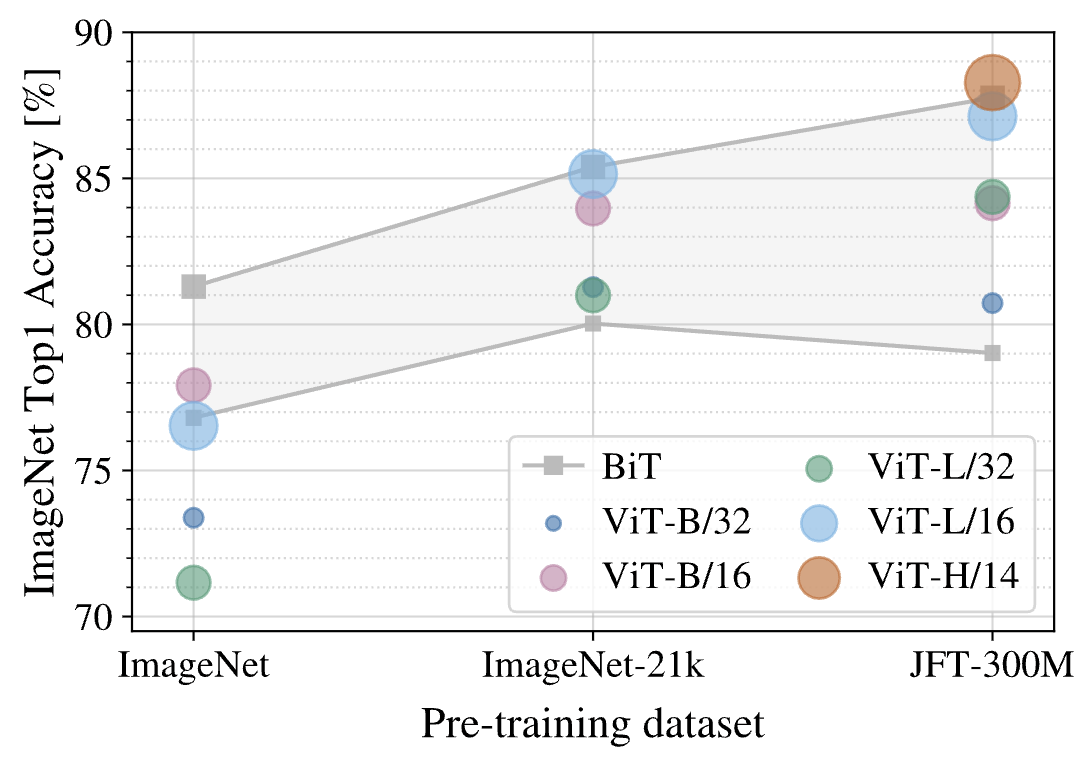
위 그림에서 회색으로 색칠되어있는 부분이 BiT 모델의 성능 범위입니다 (아마 여러 종류의 BiT로 성능을 측정해본듯 합니다). ImageNet과 같이 작은 dataset에서는 ViT의 성능이 BiT를 넘어서지 못하지만 데이터셋의 크기가 커질수록 점점 비슷해지고 결국 능가하는 것을 볼 수 있습니다. ViT의 pretraining cost가 훨씬 저렴하니 결국 ViT를 사용하는 것이 더 이득인 것을 알 수 있습니다.
두 번째는 JFT-300M의 subset으로 pretraining한 후에 ImageNet에서 Linear 5-shot accuracy를 측정하는 것입니다.
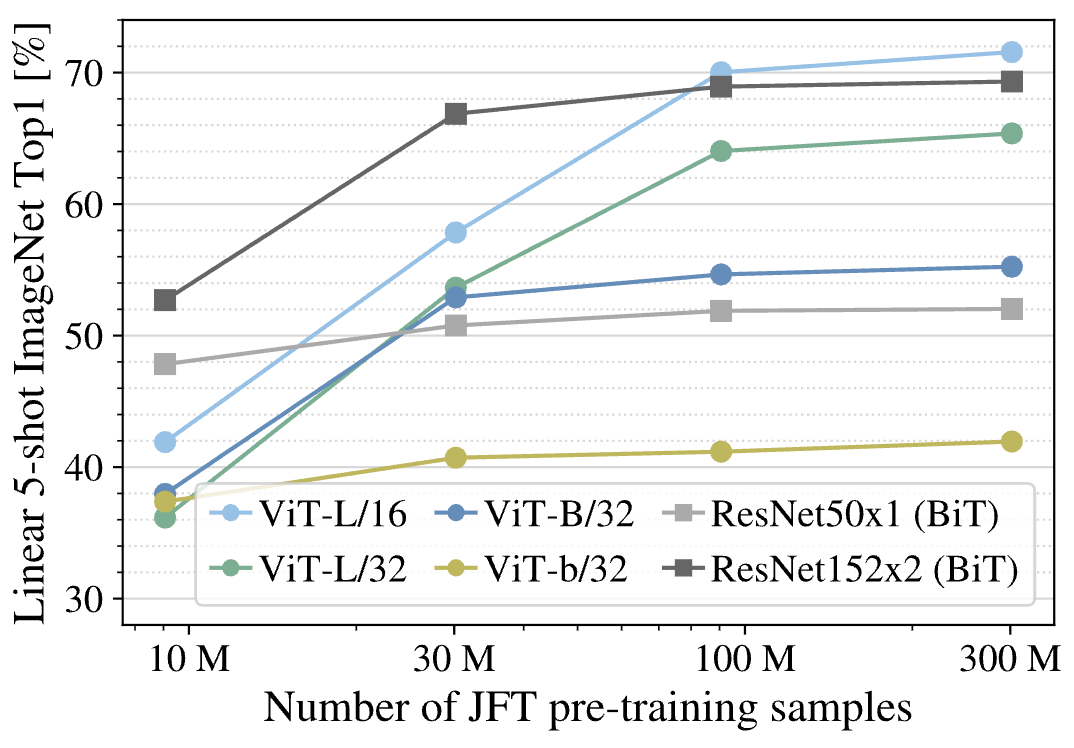
10M 정도로 pretraining size가 작을 때는 BiT가 더 성능이 좋은 것을 확인할 수 있습니다. ViT는 데이터셋의 크기가 너무 작아 일반적인 패턴을 감지하지 못하고 주어진 10M개의 데이터셋에 오버피팅된 것으로 추정됩니다. 그러나 pretraining 데이터셋 크기가 증가할 수록 점점 ViT의 성능이 좋아지는 것을 확인할 수 있습니다.
Scaling Study
BiT, ViT에 대해서 pretraining cost에 대한 transfer accuracy를 측정했습니다. Pretraining은 JFT-300M에서 진행했다고 합니다. Average-5는 transfer accuracy를 측정한 5개 데이터셋에서의 평균, ImageNet은 ImageNet에서의 transfer accuracy를 나타낸 것입니다.
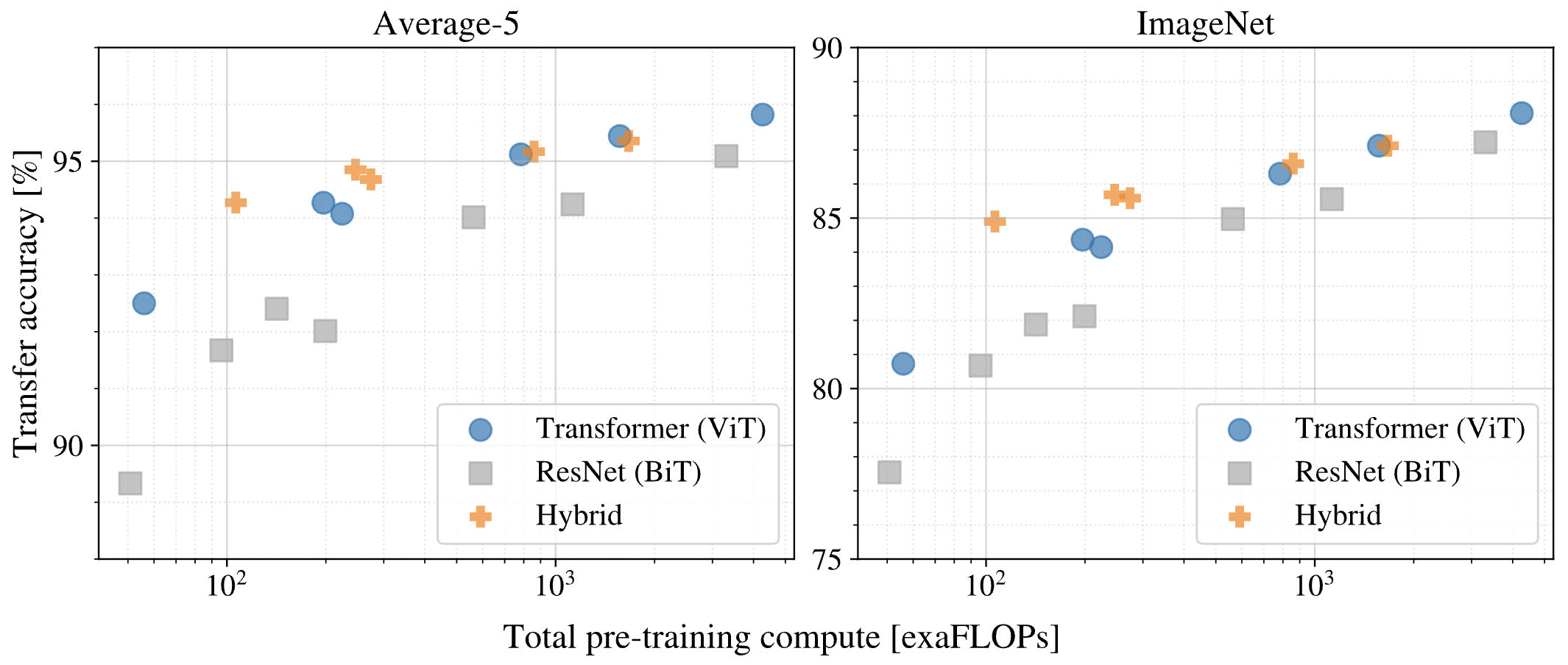
위 결과에서 아래의 결론을 얻을 수 있습니다.
- 유사한 성능을 내기까지의 pretraining cost는 ViT가 더 적다.
- Average-5에서 95%의 transfer accuracy를 얻기까지의 pretraining cost를 비교해보면 ViT가 상대적으로 매우 적은 cost만을 필요로 합니다.
- Pretraining cost가 증가할수록 Hybrid와 ViT의 차이는 적어진다.
- ViT는 pretraining cost 증가에 따라 성능이 증가하며 saturation을 확인할 수 없어 만약 더 거대한 사이즈로 pretraining하면 더 좋은 성능을 보일 가능성이 있다.
Appendix
여러 appendix 내용 중 self supervised learning, computation cost 분석에 관한 부분을 정리해보았습니다.
Self-Supervision
BERT의 방식을 적용하여 masked patch prediction task로 학습했다고 합니다. 이미지 하나별로 전체 patch sequence 중에 50%를 corrupt하는데, 그 중 80%는 learnable [MASK] embedding으로 대체하고 10%는 random patch embedding으로 대체하고 나머지 10%는 그대로 유지했다고 합니다.
이후에 sequence를 ViT를 통해 encoding하고, corrupted patch에 대해서 mean color를 예측하는 방식으로 self-supervision을 진행하게 됩니다. Ground-truth mean color는 corrupted patch에 해당하는 original patch를 이용해서 구하게 됩니다.
Training의 상세 과정은 다음과 같습니다.
- JFT 데이터셋에서 pretraining
- batch size는 4096, epoch은 14 => 대략 10000만번의 backpropagation이 진행
- Adam optimizer를 사용함
- basic learning rate: 2 x 10e-4
- 10k step까지는 warmup, 이후부터 cosine learning rate decay
- Self-supervision
- mean color prediction
- mean color & 4x4 downsized patch prediction
- full patch prediction 이후 L2 distance 측정
- corruption rate를 15%로 변경해서도 진행
위와 같이 pretraining한 후에 few-shot accuracy를 측정해본 결과 3번을 제외하고는 거의 비슷한 성능을 보였습니다(ImageNet에서 ViT-B/16이 대략 80%). 또한 corruption rate는 50%일 때가 더 성능이 높았다고 합니다.
또한 저자는 self-supervision에서는 위와 같은 enormous pretraining, large-scale dataset이 필요하지 않다고 합니다. Transfer performance가 pretraining step이 100k를 넘어간 이후부터는 감소하는 모습을 보였고, ImageNet에서 pretraining을 해도 위와 비슷한 성능을 얻을 수 있었다고 합니다.
Empirical Computation Costs
TPUv3에서 inference speed를 측정해보았다고 합니다.
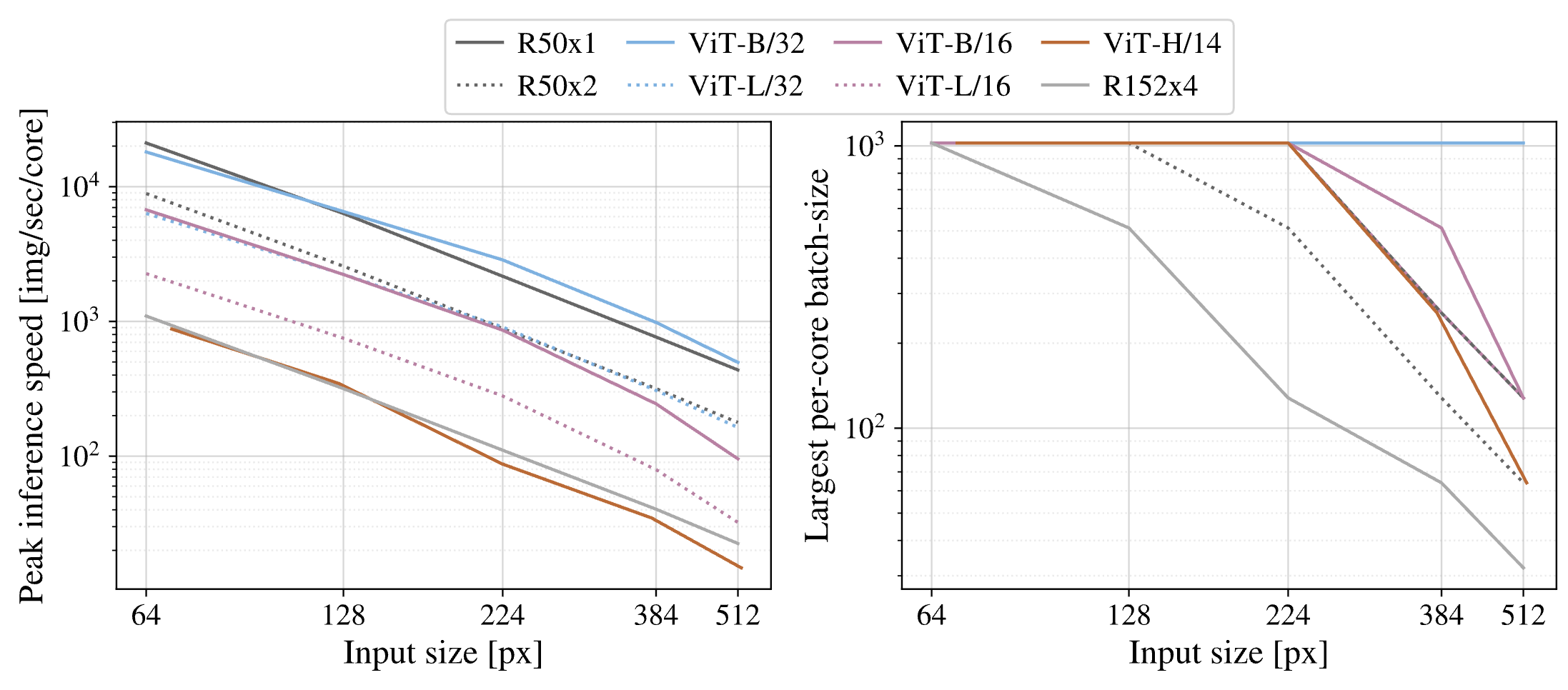
왼쪽 그림은 다양한 input image size에 대해서 각각의 모델이 TPUv3 코어 하나에서 초당 처리할 수 있는 이미지가 몇개인지에 대해 나타낸 것입니다. 오른쪽 그림은 다양한 input image size에 대해서 각각의 모델이 코어 하나에서 최대로 가질 수 있는 batch size에 대해서 나타낸 것입니다.
두 측면에서 ViT가 time/memory-efficient한 것을 확인할 수 있습니다.
Conclusion
처음에 ViT의 사전학습에 한 달이 걸린다는 것을 보고 정말 놀랐습니다. 그래서 앞으로는 Self-supervision과 같이 더 적은 데이터셋으로, 혹은 더 효율적인 학습 방법을 제시한 연구가 있는지 알아볼 것 같습니다. 또한 ResNet과 같은 mid-size dataset에서 학습된 일반적인 CNN과 ViT, BiT 등을 비교하여 어떤 상황에는 어떤 모델을 사용해보는것이 좋을 지 정리해볼 예정입니다.
읽어주셔서 감사합니다 :)